I remember the first time I encountered gnuplot. I was in my Masters program, and discovered this wonderful tool while looking for a quick way to plot data series from experiments. It was just so neat to me that I could give this application files to plot, or interactively tell it what to plot, and it would. I didn’t need to write additional code. This was especially impressive to me because at the time, I basically only knew C, C#, and Ada95 well enough to write code, and each of those required a lot more effort than gnuplot, even if you offloaded all of the drawing work to a library.
Besides this, I really liked that I could plot in a dumb terminal. This has practical benefit in some limited scenarios, but I wasn’t in any of those scenarios. The closest I came to needing this functionality was wanting to print one of my plots on a lab machine, and the lab machine only had line printer drivers, despite the fact that they printed to laser printers. But nonetheless, I found this minimalism invigorating. In that time and for several years later, I did all of my software development under Vim or Emacs, both in their out-of-the-box configuration.
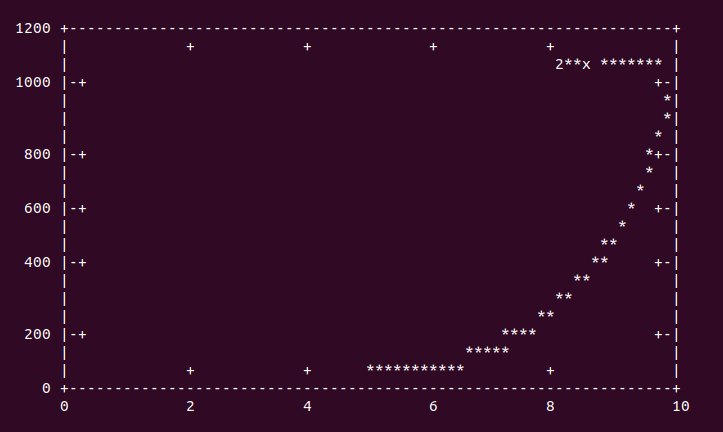
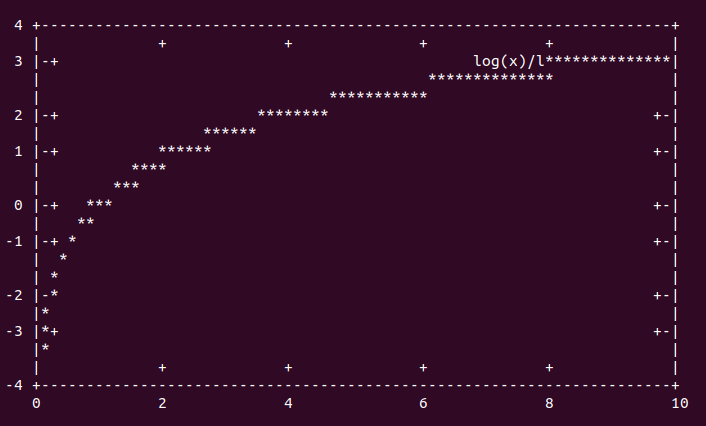
These are some pretty plain examples of function plots under gnuplot. The left is an exponential function, and the right is a logarithmic function. Notice how quickly the left one increases, and how slowly the right one does.
In my Masters program, I also had to take a remedial course; the admission requirements were that you had taken a course in software engineering. I hadn’t done this, and so in my first or second semester, I took the university’s undergraduate course in software engineering.
I do not remember much from this course, but I did latch on to a few truisms. I remember learning that there will be no silver bullet for order-of-magnitude productivity gains year over year in software development. We also spent a non-trivial amount of time discussing Brooks’ Law, which explains that adding engineers to a late project makes it later. While there are other reasons (search this page for “Kemp’s Law”) for this phenomenon, Brooks’ Law focuses primarily on the effort required to transmit information between people, and the ramp-up time required for an engineer to become productive on an in-progress project.
Of course, Brooks was discussing projects that are already late, in reflecting on his managing the software development for the IBM System/360. But the essence (hat-tip to Brooks quoting Aristotle in his use of that word) of the problem remains even when a project begins. The communication of information must be carefully cultivated in a technical project, and in a business, as both scale beyond just a few people (and as always, this is not strictly true—one need not cultivate any specific thing in a business at all, if not desired; the outcomes will be commensurate with what has been given value).
For every pair of people on a project, there is a communication path. The total number of direct communication paths in a group is expressed with a polynomial function, bounded by n^2. Consider the number of communication paths between 4, 5, 10, and 20 people involved in a project.
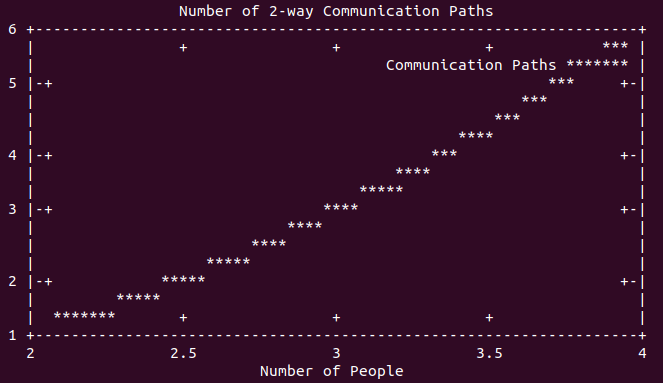
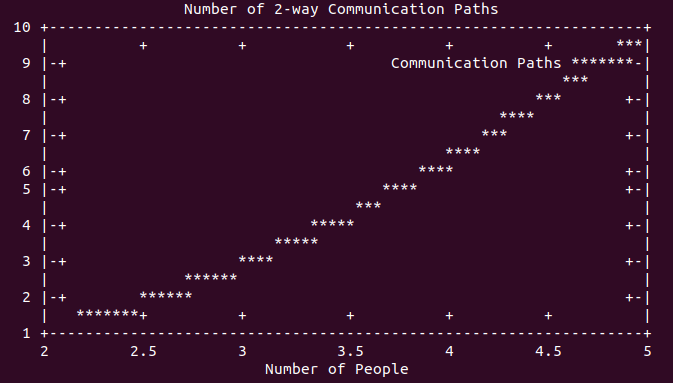
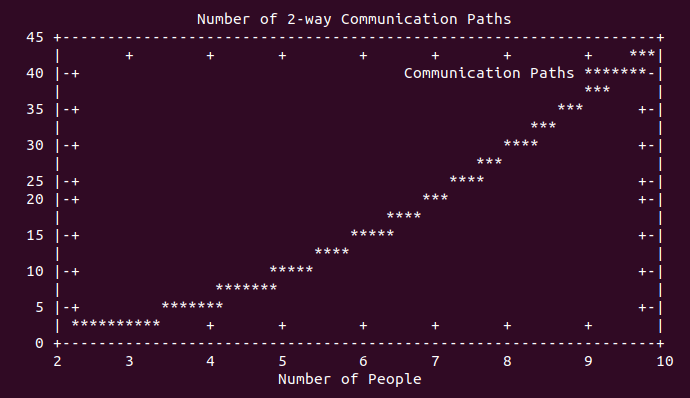
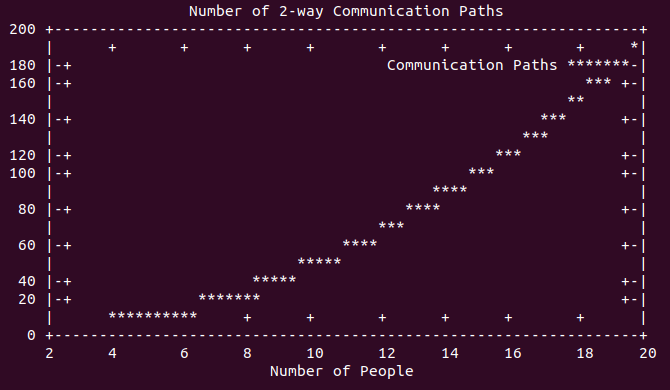
However, this is only counting the number of direct communication paths between individuals. It does not account for the number of transitive paths and loops in communication. Comically, I’ve been involved in a number of projects where outdated information is reported as the latest understanding of “the plan,” causing endless thrashing and wasted time as stale information becomes fresh again, even though it is wrong!
It’s not difficult to understand why: communications take time to propagate through a network, and if there are no safeguards in place to prevent it, a network based on social standing and trust will cause misinformation to repeat faster than the corrections to the information. Consider the full number of communication paths when also including transitive paths. Look at these plots of direct communication path count vs. indirect (transitive) path count.
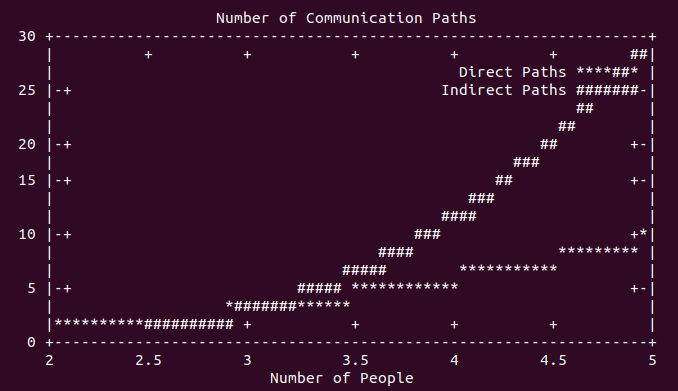
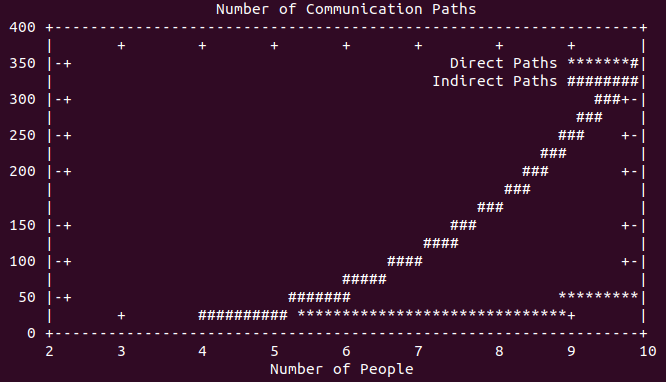
This represents the worst case, and while human communication paths are not this pathological, the problem is clear: a single source of good information will be quickly outmatched by the network effects of indiscriminate information propagation.
Early routed computer networks had this same problem, and the common solution was RIP, which ensured that updates were not sent back through the same path as they were received (split horizon), and that when a route was discovered to be faulty, it was poisoned by a router by publishing an infinite distance over the bad route so that other routers would not think that this router had an active, valid transitive route that used the bad route. Coupled with a holddown timer, which ignores all new information about a route that has gone bad until an elapsed time, the effects of bad transitive updates are mitigated.
It’s tempting to use such an algorithm and protocol for inspiration on solving communications in a company. One could imagine forcing all communications to happen through specific centralized, written channels, secured through the blockchain to guarantee that only the latest information was always being considered.
Yeah, right.
Human communication is a social activity, and the communication itself provides the outlet for innate needs around building social hierarchy and social support. Moreover, this social activity is where creativity happens. Thoughts are exchanged. Understandings are molded. Ideas meld.
As humans, we cannot help ourselves. We will seek, find, and employ the implicit communication paths in workplace social networks, to meet our social ends (as varied as they may be person to person), for the good and for the detriment of the organization or project. Including any formalism in communication inherently makes the information move slower. It is advantageous for undesirable decisions to propagate slowly through the network so that they may be corrected before making it too far, but the other side of the coin is that it is not desirable to stifle creative innovation by making it move slower.
And so communication and the use of formal mechanisms must be discriminant. Not only is it undesirable to force all project communication through official communication channels, it’s also impossible. Humans will always tend to employ communication for social needs. We would not operate well on RIP, or something that looks like RIP, because we will always find a way to employ implicit social graphs in our work. These social graphs cannot be formalized—nor would you want them to be, else your business comes to a crawl as people seek permission to make basic and simple necessary changes to a plan because they cannot self-navigate the org structures to get buy-in, or they expend tremendous time and effort solving low-priority problems.
So the cure to wild propagation of incorrect information is central communication, which is also the mechanism we must seek to avoid for both efficiency’s sake and social need. That is, it’s easy to get this wrong.
Consider the following example hierarchy, where each node represents an individual.

I have seen org charts like this in each company I’ve worked. And yet, they were often useless for aiding communication because the communication structure did not follow the hierarchy (and if your hierarchy does not exist to facilitate communication, why does it exist?). Instead, there was no communications hierarchy. The org was flat, and decisions were made by mostly-independent groups in a decentralized anarchistic style. In some cases, it was so flat that the CTO would reach out to specific individuals in the leaves of the hierarchy, or their immediate manager, and direct their activities without the context of how these people have arrived at their current understanding of problems and how they chose their solutions. But the purpose in my writing this post isn’t to discuss those issues (instead, see the post on micromanaging), it is to discuss the communication problems that happen organically.
Each change in level in an org chart is an opportunity for two-way flows of aggregated information. Each level in the tree is an opportunity for abstract views of the plan and its execution to be exchanged. When for some reason the CTO desires to dive to the deepest levels and understand the technical implementations, they should also be able view the plan documents at each level down the tree, to understand how their directives are being interpreted, and know how to alter their directives to be more clear. The same is true for any leader at any level of the hierarchy. By constructing their plans and sharing them at the same level and with the person above them, they can get feedback from their peers in their adjacent verticals and understand the implications of changes. They can also understand the relative priority of requests.
But communicating through such a structure gives other benefits.
It may seem like I’m advocating for a strict hierarchy of communication based on reporting relationships. And while I do place a lot of value in that, in some cases it isn’t possible. More than a specific managerial hierarchy, it’s important for the architectural design and plan execution to happen through explicit hierarchical channels, with each level providing an up-and-down abstracted view of the plans and the state of the execution. At the lowest level, this can look like a sprint-over-sprint scrum (or other methodology). But the tickets in these sprints have to be informed from something and consistently groomed. When the tickets are groomed, the person from the next level up in the hierarchy should be present to assert that the priorities are correct and accounted for. I think many companies have done this part well, but missed the part where the same basic activities need to happen in that next level up, officially and explicitly, in regular touch points. It should take no more than two sprints to realign an entire org against a new plan, and usually less.
But even this is only half the story. The above advice is nothing new. Typically, the the various agile and scrum activities are in place to keep the managers project managers informed of progress. While that’s good, it means that the largest body of people and the ones most critical to the company’s success have not been empowered through this process: the engineers doing the work on the front lines. Most often, the thing I have found missing in companies is a clear, easy way to view plan breakdowns across teams, to know how any one person’s work fits in with the larger plans.
Every person in existence does their job better when their incentives are aligned to their desires, and the company is aligning the work to those incentives. Frankly, many engineers find “paperwork” and process a waste of effort. After all, they seem to be able to get much more done without it. What is their incentive to take part in these activities?
The answer here is again one of incentive, but more importantly one of agency. If the process is not something that benefits the developer, then it is just another thing they have to do, or else they get in some form of trouble with their superiors. This means that they have lost agency over their work. The less agency they have, the less they are engaged with their work. The begin to execute literal orders rather than intelligently meeting the intended goals from the directives they have, and they require continual intervention (again, see the post on micromanaging).
So if the process can rob engineers of agency by not giving them proper incentives, how is this solved?
Managers, and managers-of-managers need to build a process that incentivizes agency. Agency is nothing more than giving engineers ownership over their work, and making clear the needs to give developers the room to solve them on their own. Agency is promising engineers that they do not need to seek permission to perform an activity or do work, but they are required to notify their leads of their intentions with sufficient time to understand the implications of their plans before executing, and to determine the knock-on consequences of changing plans. But this is the entire reason for having sprint retrospectives and sprint planning sessions in the first place! These give a point of reference where the feedback is due, so that the next session can be planned, and priorities made clear.
Importantly, the decomposition of plans is always kept up to date in each of these cycles, allowing engineers to choose the activities that align to the priorities, and enabling them to truly own their work. In this way, we have established agency top-to-bottom and bottom-to-top. Developers are able to navigate the communication hierarchy and make intelligent decisions, and when they make decisions or have needs, there is a clear path to report this so that priorities are kept straight and developers are not blocked. Likewise, personnel and project managers are empowered to keep a clear view of execution status and plan changes as they are driven from the ground-up. Lastly, when business priorities must change due to external influence, these changes are propagated in clear ways with clear implications, establishing mid-level leadership and leaf-level engineers’ agency to meet these new needs by making it intuitive how to navigate the communications structure in the company on their own, and centrally report the their intentions.
All of this has been done through the minimal amount of effort to keep an org aligned; such a mechanism scales up to any number of people, so long as you are willing to balance the org tree, and understand the increase in communications latency through the tree is advantageous. It optimally balances the trade offs between intentionally slowing misinformation and unintentionally slowing good ideas and information.
